AI Outtakes, Vol. 83
Jim Wrubel
CEO, Orchestra AI · March 23, 2025
Google's DeepMind Gemini 2.0 Flash model promises image editing through text commands, but experiments show it struggling with consistent and precise modifications. Through a series of tests attempting to edit an image of goths eating pancakes, the model demonstrated limitations in maintaining image quality and executing specific changes, ultimately proving not yet ready for meaningful professional use.

One of the biggest challenges and limitations with AI image generators is the "not quite" problem.
The staff here at AI Outtakes sees this daily in our work with Orchestra. Generate an image to support a blog article or social media post and it's perfect, except... One of the people depicted has six fingers, or there's a spelling issue with generated text, or the angle is wrong, or it's too dark, or too light, or not goth enough... The list goes on.
Some issues are fixable by taking the image into an editor and using the magic erase function, but for the most part the only way to "fix" the image is to mash the generate button again and hope the next version you get doesn't have the same problem, and also it doesn't have any different problems.
Ultimately what you end up with a lot of times is spamming the magic AI button until you get something that you can live with. Not very efficient!
Recently, Google introduced their DeepMind Gemini 2.0 Flash model with multimodal capability (meaning it can work with both text and images, something OpenAI has had for over a year), and reasoning. Given it's multimodal, it gives the tantalizing promise of being able to make edits to existing images by just describing the changes you want. Big, if true!
We tested OpenAI's DALL-E 3 multimodal capability back in April 2024 and found it frustratingly limited. Given almost a year and the brainpower behind one of the world's biggest companies, can Gemini 2.0 Flash do better? Let's find out!
For this experiment we're using a HuggingFace wrapper since Gemini 2.0 Flash is API-based. we're using a base prompt, a photo of three goths eating pancakes at an IHOP. Here's the first result we get:

Not a high-quality image, but it's a place to start! Now let's modify the image.
make one of the goths dressed up like santa claus

Sort of? One of them is dressed up like santa claus, but it's a totally different person. Everything in the image has been regenerated from scratch, as if behind the scenes it was just connecting the two prompts together and generating a new image. Let's see what happens when we change something else.
make a different goth be dressed up for mardi gras
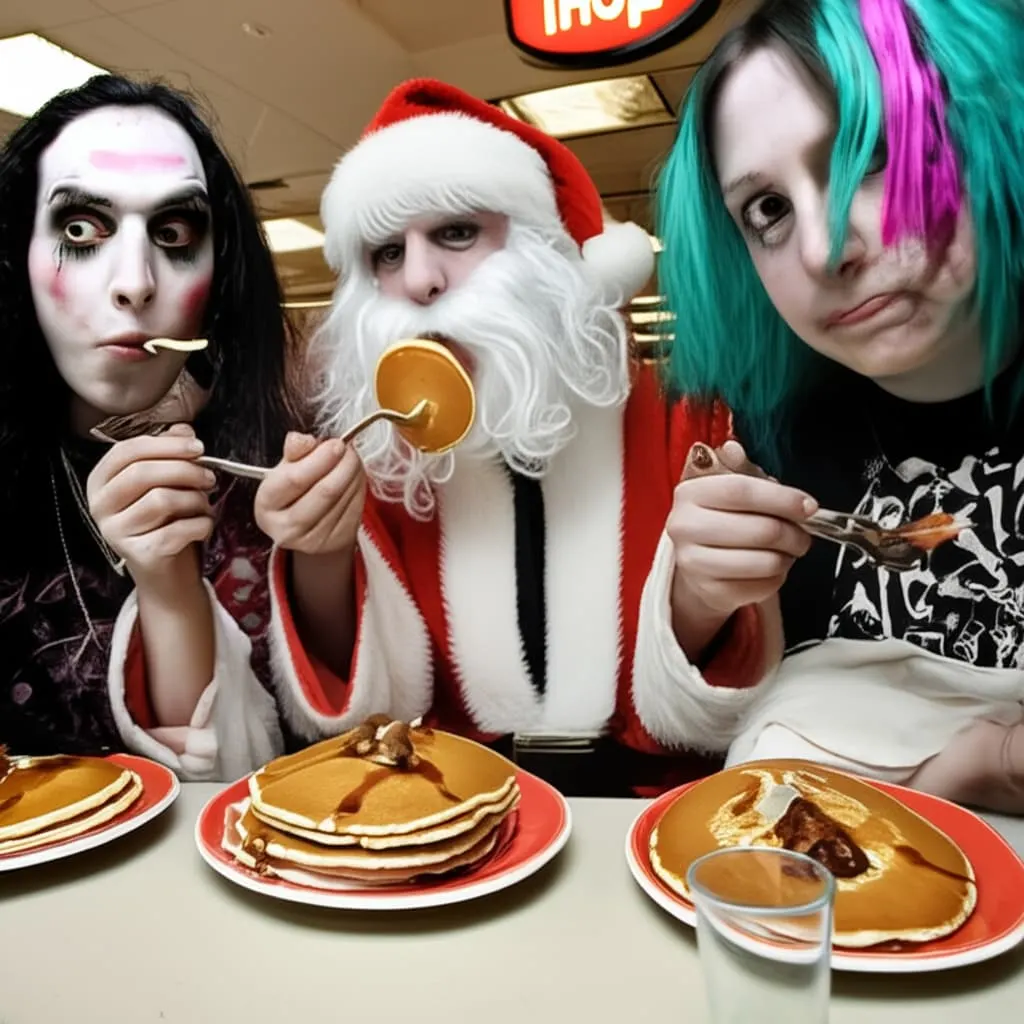
This changed the santa part but in this case the rest of the image is largely un-changed. So clearly this is something the AI could do (edit just a part of the image). Let's keep going.
make a different goth dressed up like a ghost for halloween

Now we've got one goth sort of wearing a white shirt, and the santa is a robber for some reason? Nobody's sure what's going on with the left goth who's been mean-mugging the whole time.
Let's try editing something else.
make the stack of pancakes so tall it goes out of frame

Other than the fact that they look poorly-photoshopped-in, this did what the prompt asked. So at least there's that!
make it so instead of eating pancakes they are eating frisbees

We get a different, non-frisbee related stack, still out of frame. Can't consider this a success. Also each generation makes everything look more fake, like plastic.
Did we learn anything with this experiment? Some combination of multimodal interaction and Google's Gemini 2.0 Flash model are just not ready for the type of edits that marketers, or really anyone who wants to use these tools for anything meaningful, would want to do. We'll keep an eye on these tools as they evolve, but they're definitely not ready yet.
the goths have finished eating all the pancakes are are waving goodbye



